harmony 鸿蒙OH_NN_QuantParam
OH_NN_QuantParam
Overview
Defines the quantization information.
In quantization scenarios, the 32-bit floating-point data type is quantized into the fixed-point data type according to the following formula:
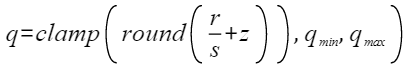
where, s and z are quantization parameters, which are stored by scale and zeroPoint in OH_NN_QuanParam. r is a floating point number, q is the quantization result, q_min is the lower bound of the quantization result, and q_max is the upper bound of the quantization result. The calculation method is as follows:
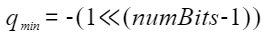
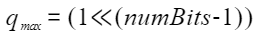
The clamp function is defined as follows:

Since: 9
Deprecated: This module is deprecated since API version 11.
Substitute: You are advised to use NN_QuantParam.
Related module: NeuralNeworkRuntime
Header file: neural_network_runtime_type.h
Summary
Member Variables
| Name | Description |
|---|---|
| uint32_t quantCount | Length of the numBits, scale, and zeroPoint arrays. In the per-layer quantization scenario, quantCount is usually set to 1. That is, all channels of a tensor share a set of quantization parameters. In the per-channel quantization scenario, quantCount is usually the same as the number of tensor channels, and each channel uses its own quantization parameters. |
| const uint32_t * numBits | Number of quantization bits. |
| const double * scale | Pointer to the scale data in the quantization formula. |
| const int32_t * zeroPoint | Pointer to the zero point data in the quantization formula. |
Member Variable Description
numBits
const uint32_t* OH_NN_QuantParam::numBits
Description
Number of quantization bits.
quantCount
uint32_t OH_NN_QuantParam::quantCount
Description
Length of the numBits, scale, and zeroPoint arrays. In the per-layer quantization scenario, quantCount is usually set to 1. That is, all channels of a tensor share a set of quantization parameters. In the per-channel quantization scenario, quantCount is usually the same as the number of tensor channels, and each channel uses its own quantization parameters.
scale
const double* OH_NN_QuantParam::scale
Description
Pointer to the scale data in the quantization formula.
zeroPoint
const int32_t* OH_NN_QuantParam::zeroPoint
Description
Pointer to the zero point data in the quantization formula.
你可能感兴趣的鸿蒙文章
harmony 鸿蒙Neural Network Runtime Kit
harmony 鸿蒙_neural_network_runtime
harmony 鸿蒙neural_network_core.h
- 所属分类: 后端技术
- 本文标签:
热门推荐
-
2、 优质文章
-
3、 gt
-
7、 openharmony
-
9、 golang
-
10、 Vue中input框自动聚焦