content: 后端,Java,架构
title: 优秀的后端应该有哪些好的开发习惯? shortTitle: 优秀的后端应该有哪些开发习惯? description: 前言 毕业快三年了,前后也待过几家公司,碰到各种各样的同事。见识过各种各样的代码,优秀的、垃圾的、不堪入目的、看了想跑路的等等,所以这篇文章记录一下一个优秀的后端 Java 开发应该有哪些好的开发习惯 tags: - 优质文章 author: 暮色妖娆丶 category: - 掘金社区 head: - - meta - name: keywords
content: 后端,Java,架构
工作快12年了,前后待过几家公司,碰到各种各样的同事,见识过各种各样的代码,优秀的、垃圾的、不堪入目的、看了想跑路的等等,所以这篇文章记录一下一个优秀的后端 Java 开发应该有哪些好的开发习惯。
希望能给各位工作党的球友一点点帮助,在校的学生党也可以提前感受一下。
拆分目录结构
受传统 MVC 模式的影响,以前的做法大多是几个固定的文件夹 controller、service、mapper、entity,然后无限制添加,到最后你就会发现一个 service 文件夹下面有几十上百个 Service 类,根本没法分清业务模块。
正确的做法是在写 service 上层新建一个 modules 文件夹,在 moudles 文件夹下根据不同业务建立不同的包,在这些包下面写具体的 service、controller、entity、enums 包或者继续拆分。
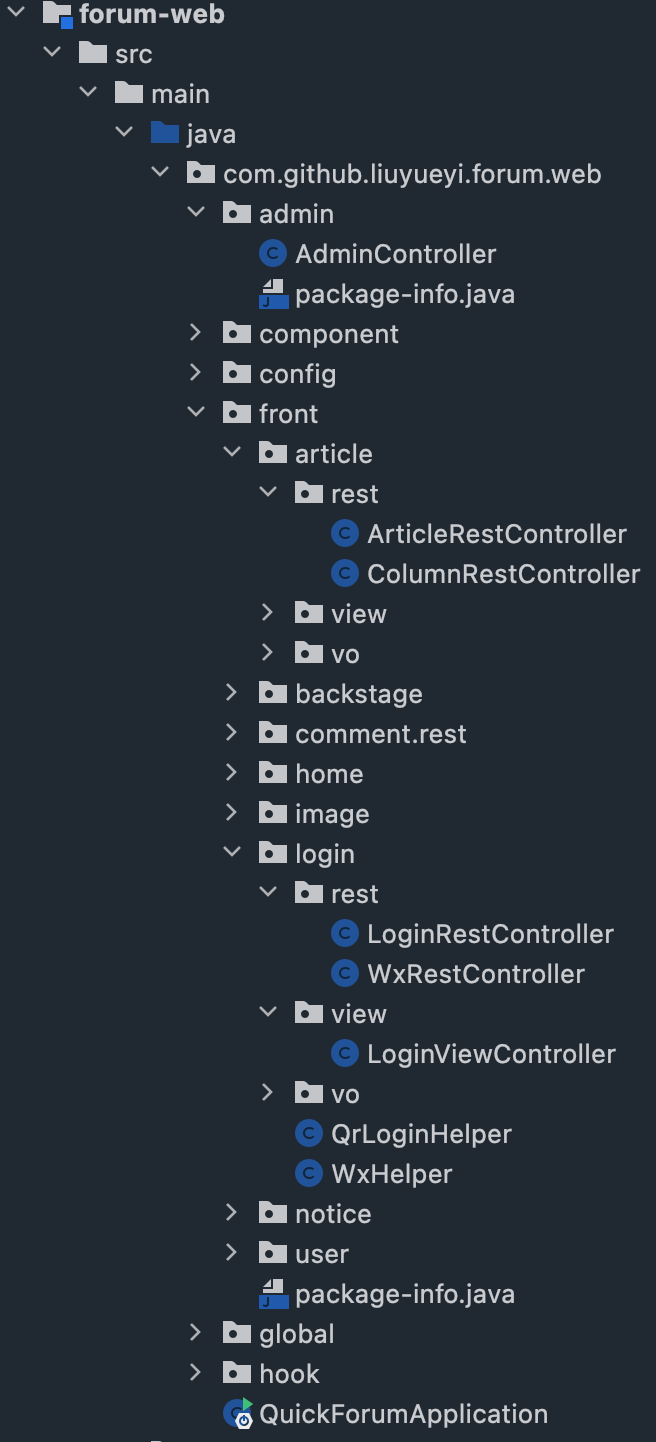
等以后开发版本迭代,如果某个包可以继续拆领域就继续往下拆,可以很清楚的一览项目业务模块。后续拆微服务也简单。
封装方法形参
当你的方法形参过多时请封装一个对象出来…… 下面是一个反面教材,谁特么教你这样写代码的!
public ResVo<NextPageHtmlVo> list(long customerId, String channelKey,
String androidId, String imei, String gaId,
String gcmPushToken, String instanceId) {}
写个对象出来:
public ResVo<NextPageHtmlVo> list(@RequestBody ArticlePostReq req, HttpServletResponse response) throws IOException {
}
为什么要这么写?
比如你这方法是用来查询的,万一以后加个查询条件是不是要修改方法?每次加个参数就要改方法参数列表,简直作死。封装个对象,以后无论加多少查询条件都只需要在对象里面加字段就行,而且关键是看起来代码也很舒服啊!
封装业务逻辑
如果你看过“屎山”你就会有深刻的感触,这特么一个方法能写几千行代码,还无任何规则可言……往往负责的人会说,这个业务太复杂,没有办法改善,实际上这都是懒的借口。不管业务再复杂,我们都能够用合理的设计、封装去提升代码可读性。下面贴两段高级开发(假装自己是高级开发)写的代码
@RequestMapping(path = "list")
public ResVo<NextPageHtmlVo> list(@RequestParam(value = "category", required = false) String category,
@RequestParam(value = "tag", required = false) String tag,
@RequestParam(name = "page") Long page,
@RequestParam(name = "size", required = false) Long size) {
if (StringUtils.isBlank(category) && StringUtils.isBlank(tag)) {
return ResVo.fail(StatusEnum.ILLEGAL_ARGUMENTS_MIXED, "category|tag miss!");
}
size = Optional.ofNullable(size).orElse(PageParam.DEFAULT_PAGE_SIZE);
size = Math.min(size, PageParam.DEFAULT_PAGE_SIZE);
Long categoryId = categoryService.queryCategoryId(category);
PageListVo<ArticleDTO> articles = articleReadService.queryArticlesByCategory(categoryId, PageParam.newPageInstance(page, size));
String html = templateEngineHelper.renderToVo("biz/article/list", "articles", articles);
return ResVo.ok(new NextPageHtmlVo(html, articles.getHasMore()));
}
/**
* 新建文章
*
* @param article
* @param content
* @param tags
* @return
*/
private Long insertArticle(ArticleDO article, String content, Set<Long> tags) {
// article + article_detail + tag 三张表的数据变更
articleDao.save(article);
Long articleId = article.getId();
articleDao.saveArticleContent(articleId, content);
articleTagDao.batchSave(articleId, tags);
// 发布文章,阅读计数+1
userFootService.saveOrUpdateUserFoot(DocumentTypeEnum.ARTICLE, articleId, article.getUserId(), article.getUserId(), OperateTypeEnum.READ);
return articleId;
}
这段两代码虽然还算不上多复杂,但是不同水平的人写出来就完全不同,不得不赞一下这个业务的拆分和方法的封装。一个大业务里面有多个小业务,不同的业务调用不同的 service 方法即可,后续接手的人即使没有流程图等相关文档也能快速理解这里的业务。
很多初级开发写出来的业务方法就是上一行代码是 A 业务的,下一行代码是 B 业务的,在下面一行代码又是 A 业务的,业务调用之间还嵌套这一堆单元逻辑,显得非常混乱,代码还多。
判断集合类型不为空的正确方式
很多人喜欢写这样的代码去判断集合
if (list == null || list.size() == 0) {
return null;
}
当然你硬要这么写也没什么问题……但是不觉得难受么,现在框架中随便一个 jar 包都有集合工具类,比如 org.springframework.util.CollectionUtils、com.baomidou.mybatisplus.core.toolkit.CollectionUtils 。
以后请这么写(如果非要说里面也是封装的判 null 和 size 为 0,那就是硬杠了)
if (CollectionUtils.isEmpty(list) || CollectionUtils.isNotEmpty(list)) {
return null;
}
集合类型返回值不要 return null
当你的业务方法返回值是集合类型时,请不要返回 null,正确的操作是返回一个空集合。你看 mybatis 的列表查询,如果没查询到元素返回的就是一个空集合,而不是 null。否则调用方得去做 NULL 判断,多数场景下对于对象也是如此。
映射数据库的属性尽量不要用基本类型
我们都知道 int/long 等基本数据类型作为成员变量默认值是 0。现在流行使用 mybatisplus 、mybatis 等 ORM 框架,在进行插入或者更新的时候很容易会带着默认值插入更新到数据库。我特么真想砍了之前的开发,重构的项目里面实体类里面全都是基本数据类型。当场裂开……
封装判断条件
public void method(LoanAppEntity loanAppEntity, long operatorId) {
if (LoanAppEntity.LoanAppStatus.OVERDUE != loanAppEntity.getStatus()
&& LoanAppEntity.LoanAppStatus.CURRENT != loanAppEntity.getStatus()
&& LoanAppEntity.LoanAppStatus.GRACE_PERIOD != loanAppEntity.getStatus()) {
//...
return;
}
这段代码的可读性真的很差,这 if 里面谁知道干啥的?我们用面向对象的思想去给 loanApp 这个对象里面封装个方法不就行了么?
public void method(LoanAppEntity loan, long operatorId) {
if (!loan.finished()) {
//...
return;
}
LoanApp 这个类中封装一个方法,简单来说就是这个逻辑判断细节不该出现在业务方法中。
/**
* 贷款单是否完成
*/
public boolean finished() {
return LoanAppEntity.LoanAppStatus.OVERDUE != this.getStatus()
&& LoanAppEntity.LoanAppStatus.CURRENT != this.getStatus()
&& LoanAppEntity.LoanAppStatus.GRACE_PERIOD != this.getStatus();
}
控制方法复杂度
推荐一款 IDEA 插件 CodeMetrics ,它能显示出方法的复杂度,它是对方法中的表达式进行计算,布尔表达式,if/else 分支,循环等。
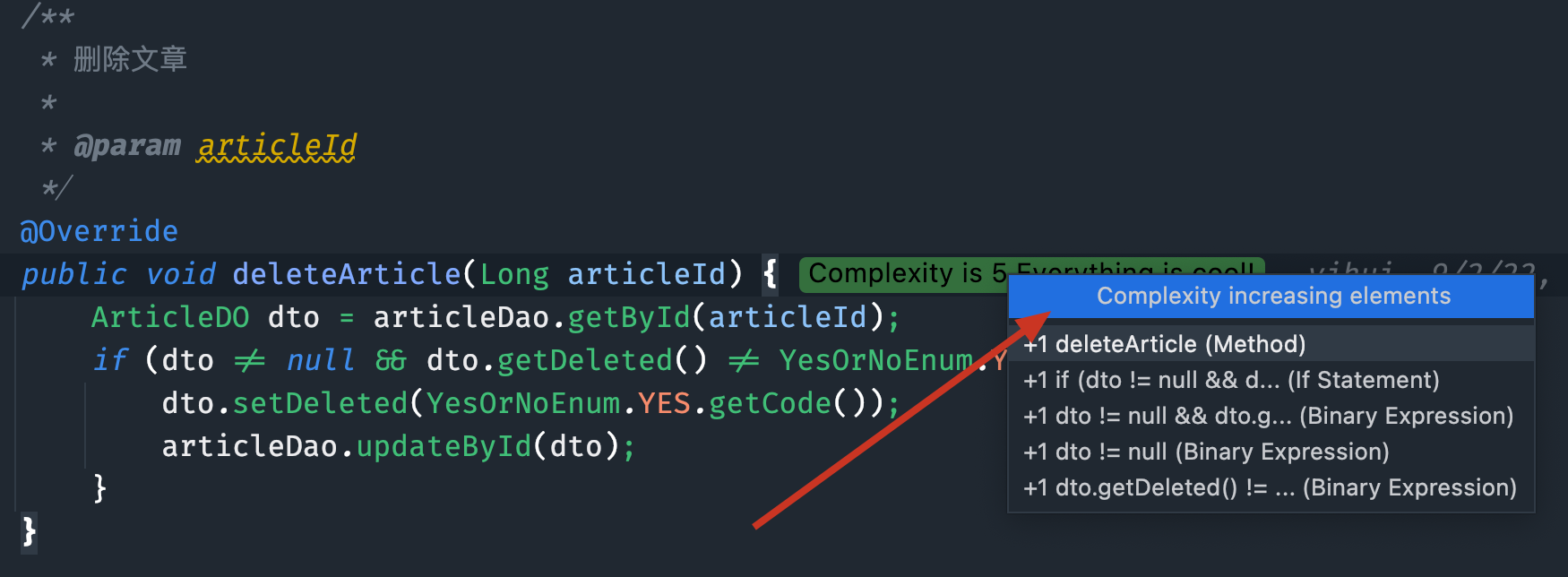
点击可以查看哪些代码增加了方法的复杂度,可以适当参考,毕竟我们通常写的是业务代码,在保证正常工作的前提下最重要的是要让别人能够快速看懂。当你的方法复杂度超过 10 就要考虑是否可以优化了。
使用 @ConfigurationProperties 代替 @Value
之前居然还看到有文章推荐使用 @Value 比 @ConfigurationProperties 好用的,吐了,别误人子弟。
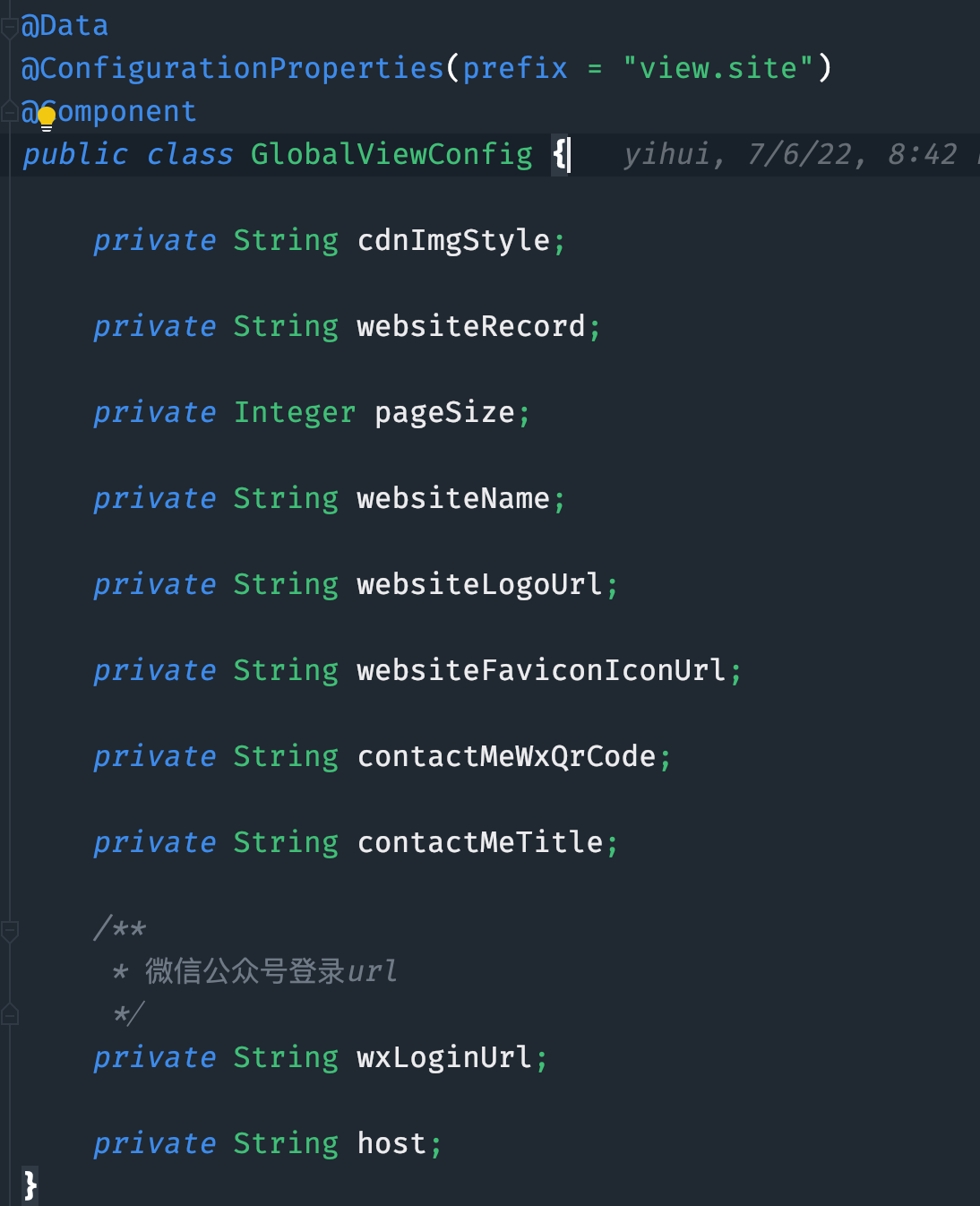
列举一下 @ConfigurationProperties 的好处。
- 在项目
application.yml配置文件中按住 ctrl + 鼠标左键点击配置属性可以快速导航到配置类。写配置时也能自动补全、联想到注释。需要额外引入一个依赖org.springframework.boot:spring-boot-configuration-processor。
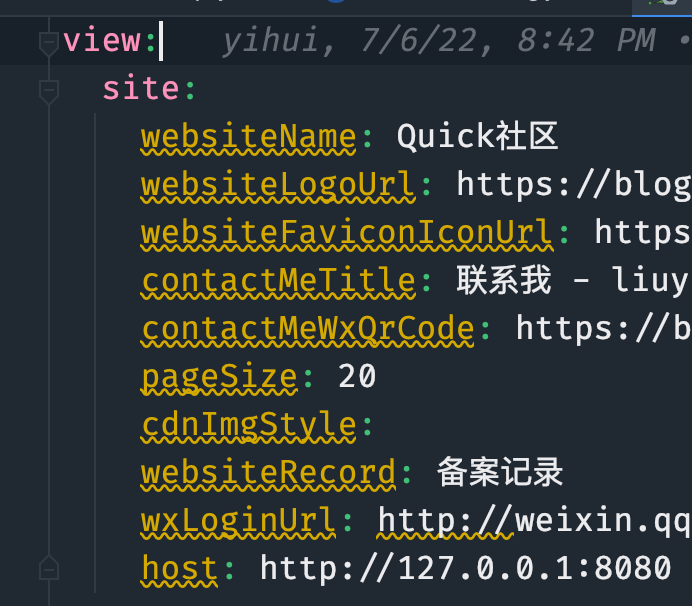
@ConfigurationProperties 支持 NACOS 配置自动刷新,使用 @Value 需要在 BEAN 上面使用 @RefreshScope 注解才能实现自动刷新
@ConfigurationProperties 可以结合 Validation 校验,@NotNull、@Length 等注解,如果配置校验没通过程序将启动不起来,及早的发现生产丢失配置等问题。
@ConfigurationProperties 可以注入多个属性,@Value 只能一个一个写
@ConfigurationProperties 可以支持复杂类型,无论嵌套多少层,都可以正确映射成对象
相比之下我不明白为什么那么多人不愿意接受新的东西,裂开……你可以看下所有的 springboot-starter 里面用的都是 @ConfigurationProperties 来接配置属性。
推荐使用 lombok
当然这是一个有争议的问题,我的习惯是使用它省去 getter、setter、toString 等等。
不要在 AService 调用 BMapper
我们一定要遵循从 AService -> BService -> BMapper,如果每个 Service 都能直接调用其他的 Mapper,那特么还要其他 Service 干嘛?老项目还有从 controller 调用 mapper 的,把控制器当 service 来处理了。。。
尽量少写工具类
为什么说要少写工具类,因为你写的大部分工具类,在你无形中引入的 jar 包里面就有,String 的,Assert 断言的,IO 上传文件,拷贝流的,Bigdecimal 的等等。自己写容易错还要加载多余的类。
不要包裹 OpenFeign 接口返回值
搞不懂为什么那么多人喜欢把接口的返回值用 Response 包装起来……加个 code、message、success 字段,然后每次调用方就变成这样
CouponCommonResult bindResult = couponApi.useCoupon(request.getCustomerId(), order.getLoanId(), coupon.getCode());
if (Objects.isNull(bindResult) || !bindResult.getResult()) {
throw new AppException(CouponErrorCode.ERR_REC_COUPON_USED_FAILED);
}
这样就相当于
- 在 coupon-api 抛出异常
- 在 coupon-api 拦截异常,修改 Response.code
- 在调用方判断 response.code 如果是 FAIELD 再把异常抛出去……
你直接在服务提供方抛异常不就行了么。。。而且这样一包装 HTTP 请求永远都是 200,没法做重试和监控。当然这个问题涉及到接口响应体该如何设计,目前网上大多是三种流派
- 接口响应状态一律 200
- 接口响应状态遵从 HTTP 真实状态
- 佛系开发,领导怎么说就怎么做
不接受反驳,我推荐使用 HTTP 标准状态。特定场景包括参数校验失败等一律使用 400 给前端弹 toast。下篇文章会阐述一律 200 的坏处。
OpenFeign 接口不建议打成 jar
见过很多使用 OpenFeign 的接口是这样用的,将 OpenFeign 接口写在服务提供方,打成 jar。比如服务 A 调用 B,在 B 项目单独开一个 module 写接口定义,打出一个 jar 包让 A 引入依赖。
让我们来感受一下调用一个 Feign 接口实现的步骤:
- 在 B 服务中写
Controller实现 - 在 B 服务中定义
OpenFeign接口定义 - 在 B 服务中修改 jar 版本 +1,打一个 jar 包到本地仓库
- 在 A 服务中修改依赖 jar 版本,刷新
maven/gradle
乍一看不麻烦是吧?但是你要知道我们开发中经常会出现丢参数、缺响应属性等情况,一旦有任何小问题,都要重新走一遍上述流程。。。。
建议将 OpenFeign 接口定义在消费端 A,B 只需要提供一个接口实现即可。所不好的地方无非是 XxxRequest、XxxResponse 类冗余了一份,但其实并没有什么问题,因为对于 Feign 来说请求和响应的 BO 类并不需要字段完全一致,它的解码器会智能的解析响应并封装到你的 XxxResponse 接收类中。
你这么理解就明白了,这个类 XxxRequest、XxxResponse 等,仅仅是你的 A 服务为了映射请求结果而本地自定义的一个映射数据结构,这个映射数据结构和 B 服务可以说是没关系的。所以你当然应该放在 A 这里。
你很纠结无非是你觉得这个东西似乎是可以复用的,所以纠结放 A 还是放 B,以及是不是要抽出来做个公共依赖。我很久以前也很纠结这个东西,但是踩了太多坑以后我的想法就变了,高内聚低耦合本质的意义,就是把和一个服务(组件,应用,包,等等等等)相关的代码全部包在一起,不要和外界有牵扯,你有牵扯就会引发修改时的依赖地狱。
写有意义的方法注释
这种注释你写出来是怕后面接手的人瞎么……你在后面写字段参数的意义啊……
/**
* 请求电话验证
*
* @param credentialNum
* @param callback
* @param param
* @return phoneVerifyResult
*/
public void method(String credentialNum,String callback,String param,String phoneVerifyResult){
}
要么就别写,要么就在后面加上描述……写这样的注释被 IDEA 报一堆警告看着不难受?
和前端交互的 DTO 对象命名
什么 VO、BO、DTO、PO 我倒真是觉得没有那么大必要分那么详细,至少我们在和前端交互的时候类名要起的合适,不要直接用映射数据库的类返回给前端,这会返回很多不必要的信息,如果有敏感信息还要特殊处理。
推荐的做法是接受前端请求的类定义为 XxxRequest,响应的定义为 XxxResponse。以订单为例:接受保存更新订单信息的实体类可以定义为 OrderRequest,订单查询响应定义为 OrderResponse,订单的查询条件请求定义为 OrderQueryRequest。
不要跨服务循环访问数据库
跨服务查询时,如果有批量数据查询的场景,直接写一个批量的 Feign 查询接口,不要像下面这样
list.foreach(id -> {
UserResponse user = userClient.findById(id);
});
因为每一次 OpenFeign 的请求都是一个 Http 请求、一个数据库 IO 操作,还要经过各种框架内的拦截器、解码器等等,全都是损耗。
直接定义一个批量查询接口
@PostMapping(\"/user/batch-info\")
List<UserResponse> batchInfo(@RequestBody List<Long> userIds);
这就结束了吗?并没有,如果你遇到这种 userIds 的数量非常大,在 2000 以上,那么你在实现方就不能在数据库中直接用 in() 去查询。在实现方要拆分这个 useIds 。有索引的情况下 in() 1000 个元素以下问题不大。
public List<XxxResponse> list(List<Long> userIds) {
List<List<Long>> partition = Lists.partition(userIds, 500); //拆分 List
List<XxxResponse> list = new ArrayList<>();
partition.forEach(item -> list.addAll(xxxMapper.list(item)));
return list;
}
尽量别让 IDEA 报警
我是很反感看到 IDEA 代码窗口一串警告的,非常难受。因为有警告就代表代码还可以优化,或者说存在问题。
前几天捕捉了一个团队内部的小 bug,其实本来和我没有关系,但是同事都在一头雾水的看外面的业务判断为什么走的分支不对,我一眼就扫到了问题。

因为 java 中整数字面量都是 int 类型,到集合中就变成了 Integer,然后 stepId 点上去一看是 long 类型,在集合中就是 Long,那这个 contains 妥妥的返回 false,都不是一个类型。
你看如果注重到警告,鼠标移过去看一眼提示就清楚了,少了一个生产 bug。
尽可能使用新技术组件
我觉得这是一个程序员应该具备的素养……反正我是喜欢用新的技术组件,因为新的技术组件出现必定是解决旧技术组件的不足,而且作为一个技术人员我们应该要与时俱进~~ 当然前提是要做好准备工作,不能无脑升级。举个最简单的例子,Java 17 都出来了,新项目现在还有人用 Date 来处理日期时间……
结语
这篇内容大部分参考了掘金上一个网友的代码案例,我基本上每条都在本地代码库里查了一遍,还不错,基本上遵循了这些优秀的开发习惯,也希望球友们都能参照。做个优雅的代码骑士。
参考链接:https://juejin.cn/post/7072252275002966030,整理:沉默王二
你可能感兴趣的文章
热门推荐
-
2、 优质文章
-
3、 gt
-
7、 openharmony
-
9、 golang
-
10、 Vue中input框自动聚焦