Kafka架构原理及存储机制
介绍kafka的架构原理,工作流程以及存储机制,然后讲解了kafka为什么这么高性能高吞吐的原因及优化的点。
架构
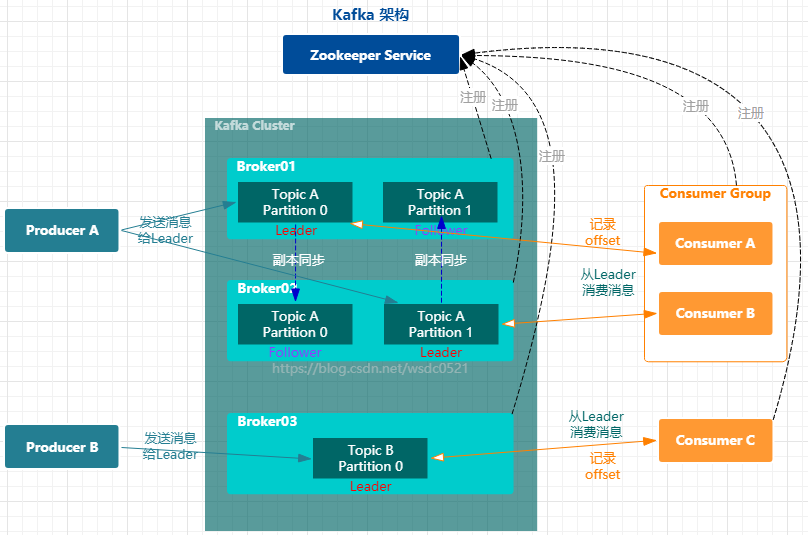
- Producer:消息生产者,向Kafka Broker发送消息;
- Consumer:消息消费者,从Kafka Broker读取消息;
- Consumer Group:消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由同一个组内的一个消费者消费;跨消费者组之间互不影响;
- Broker:消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群,一个Broker可以容纳多个 topic;
- Topic:主题,Kafka根据topic对消息进行分类,生产者和消费者面对的都是Topic;
- Partition:分区,为了实现可扩展性,一个topic可以分为多个partition 分布到不同的broker之上,每个partition都是有序队列;
- Replication:副本,为了实现高可用,保证集群中的某个节点发生故障时,该节点上的partition 数据不丢失且kafka能正常提供服务,kafka提供副本机制,topic内的每个分区可以设置若干个副本(包含leader和follower);
- Leader:topic内分区副本的主副本,生产者的数据发送给Leader,消费者也是从Leader中消费数据;
- Follower:topic内分区副本的从副本,实时从主副本中同步数据,保证和主副本的数据一致性,当主副本出现故障时,某个follower会成为新的Leader,Follower副本不接收生产者消费者的读写请求。
- Zookeeper:帮助kafka维护Broker的控制器节点以及topic元数据信息,帮助控制器进行分区副本的选举;
注意:
- kafka的副本数量不能大于broker节点数量。kafka的副本数量和HDFS的副本数量是有区别的。
- HDFS的副本数量表示为最大副本数量,当DataNode节点数量小于设置的副本数量时没有任何问题,当新增DataNode时候如果副本数量没达到要求会自动复制副本。
- 而kafka的副本数量表示为该topic的副本数量,当副本数量大于broker节点数量时会报错,这是因为分区是以目录存储在各个broker节点的data目录下,命名为:topicName-分区编号。当副本数量大于broker节点时就表示在同一个Broker节点的data目录下有两个一样的文件夹,这是不允许的。
- kafka的分区数量可以大于broker节点数量,当分区数量大于broker节点数量时,在broker节点的data目录下会有同一个topic的两个分区的数据,如:topicName-0,topicName-1。
- 消费者组内的消费者的数量不要设置大于该消费者组订阅的所有topic的分区总数,这是由于该消费者组订阅的topic的每个分区只能被消费者组内的一个消费者所消费,当消费者组内的消费者数量大于订阅的topic的总分区数量时就会造成有消费者没有分区数据消费的情况,会造成资源的浪费。
- kafka只保证分区内有序,不能保证全局有序。每个分区内有自己的Offset,并不是全局的offset。
在上图中我们也可以看出,生产者只会往分区副本中的Leader发送数据,消费者也只会从分区副本中的Leader读取数据,分区副本中的Follower从Leader内同步数据,尽量保持和Leader副本的数据一致。当多个消费者在同一个消费者组的时候,组内的每个消费者不能消费同一个分区数据,即某个topic内的某个分区只能被在同一消费者组内的一个消费者所消费,当跨消费者组时,可以被其他消费者组内的消费者消费。消费者每当消费一条数据都会往kafka记录一个offset偏移量,记录该消费者所消费的topic分区已经消费到的位置,便于下次重新消费时可以继续消费。(在0.90版本之前该offset信息是维护在zk内,在0.90之后不建议再使用zk保存该offset信息,而是维护在kafka内的一个系统topic中:__consumer_offsets)。Broker和消费者组都会向ZK进行注册,将元数据信息维护在ZK内。
工作流程
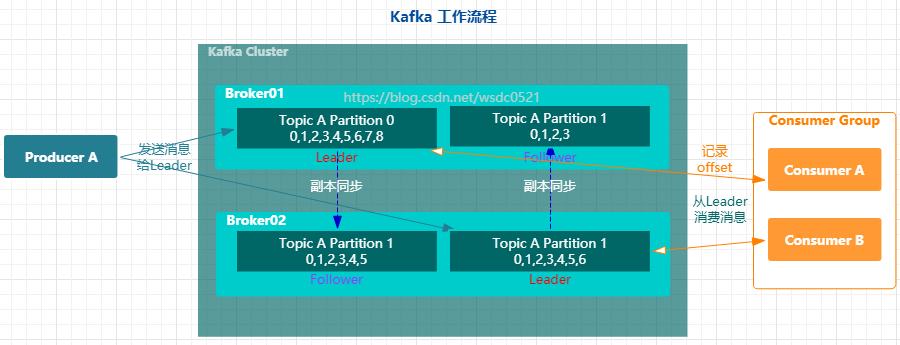
kafka中的消息以topic进行分类,同时消费者和生产者都是面向topic读写消息的,更细粒度的来说,它们面对的是topic内分区的主副本,topic仅仅是逻辑上的划分,而partition是物理上存储的划分。
在上面我们提到消费者和生产者都是直接面向topic内分区的主副本,从副本从主副本同步数据,因此从副本的数据和主副本的数据会有延迟,如上图显示了一个topicA有两个分区,每个分区有2个副本(leader和follower),其中分区0的主副本内的offset为0~8,分区0的从副本的offset为0~5,分区1的主副本内的offset为0~6,分区1的从副本的offset为0~3。
每个分区在物理上是按文件夹区分的,在分区文件夹内有多个.log和.index文件,同名的.log和.index一一对应,.log文件内存储着生产者发送给该分区的实际数据和offset,每当生产者发送数据都会追加到.log文件的末端,.index内存储着.log文件的索引数据以提升消费者查询数据的性能。消费者从.log文件消费数据之后会往__consumer_offset这个系统topic内记录自己已读取的offset(偏移量)。
控制器
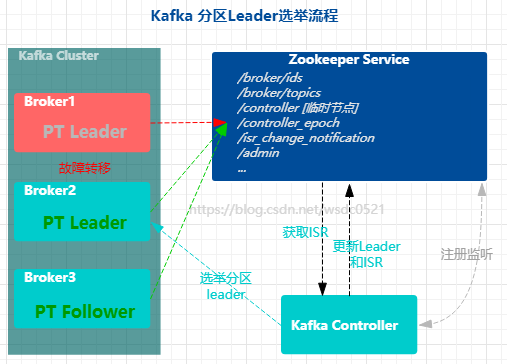
上面提到了消费者和生产者都是直接面向topic内分区(partition)的主副本(Leader),从副本(Follower)从主副本同步数据,当Leader副本出现故障时会进行选举,将某一个Follower副本升级为Leader副本继续提供读写服务。这里就涉及到了Controller(控制器)。
集群内broker通过zk内的/broker/ids 节点互相通信:
在前一篇安装Kafka集群的时候我们在配置文件中并没有指向其他的kafka节点,但却能搭建集群,是因为 server.properties 文件内配置了zk服务器,每个kafka broker节点通过配置的zk服务器注册到zk内的 /broker/ids 节点内,在该节点内的broker自动成为一个kafka集群。
集群内broker通过zk内的/controller 节点成为控制器节点:
同时当broker启动时会去抢占zk内的一个临时Znode节点 /controller,抢占成功的broker自动成为该kafka集群的Controller节点,在一个时间点内,一个kafka集群内只允许有一个Controller节点,当该controller节点发生故障时,其他broker节点也会去抢占该临时节点,抢占成功的Broker又会自动成为controller节点。
kafka通过zk内的/controller_epoch 节点保证控制器的唯一性和操作一致性:
在zk内还有一个和控制器相关的永久节点 /controller_epoch,它记录着控制器变更的次数(纪元),初始值为1,每发生一次控制器节点的变更该值都会加1,每个和控制器交互的请求都会携带上controller_epoch这个值,如果请求的controller_epoch值小于控制器内存中的controller_epoch值,则认为这个请求是向已经过期的控制器所发送的请求,该请求就会被认定为无效的请求。如果请求的controller_epoch值大于控制器内存中的controller_epoch值,那么则说明已经有新的控制器当选了(脑裂),旧的控制器会主动下线。因此,Kafka通过controller_epoch来保证控制器的全局唯一性,进而保证相关操作的一致性。
Controller节点除了要负责和其他Broker节点一样的工作之外还需要负责下面的工作:
- 处理分区重分配;
- 处理分区副本的Leader选举;
- 更新集群内元数据信息;
- 启动和管理分区副本状态机;
- 监控broker、topic、partition的变化行为;
存储机制
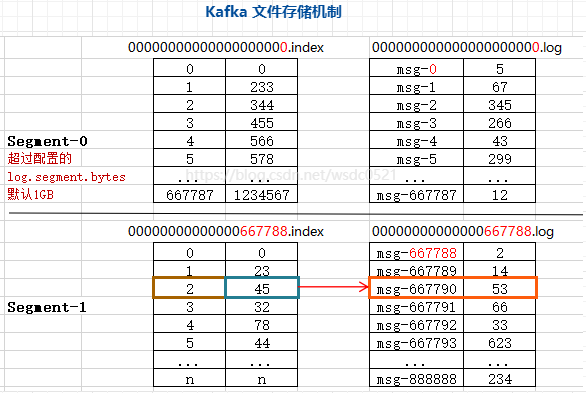
在上面提到kafka的topic是逻辑概念,partition是真实存储的物理概念,kafka通过 分段 + 索引 的方式提升查找效率。在磁盘上每个分区的数据是以文件夹的形式存储在broker节点的/data目录下,在每个partition(分区)下划分为多个segment(段),每个segment又分为一个.index文件和一个.log文件,.log文件内存储着生产者发送给该分区的实际数据和offset,每当生产者发送数据都会追加到.log文件的末端,.index内存储着.log文件的索引数据以提升消费者查询数据的性能。log文件大小在 server.properties 文件中可以配置。log.segment.bytes=1073741824(默认1GB),每当log文件达到配置的阈值就会新增一个segment(log文件和index文件)。
如上图展示了一个分区下的两个segment,其中segment-0已满配置的1GB大小,新来的数据进入segment-1。
命名方式:.index和.log文件名以当前segment所包含的最小的Offset值,长度20,不足的部分以0补全,如segment-0表示该段是从offset-0开始记录,segment-1表示该段从offset-667788开始记录。
.index文件:包含了.log数据文件的索引,建立offset到数据实际物理地址之间的映射关系,方便快速定位消息所在的物理文件位置。.log文件内各个消息体大小不一,非常影响检索的效率,而.index文件是固定格式长度的,因此利用二分查找法可以快速定位索引数据;
.log文件:存储实际消息数据,每条消息有固定格式:偏移量offset(8 Bytes)、消息体的大小(4 Bytes)、循环冗余校验crc32(4 Bytes)、版本号magic(1 Byte)、编码压缩attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、消费消息长度payload length(4 Bytes)等字段,通过这些值可以确定一条消息的大小;
定位数据的步骤:例如我们想要找offset为667790这条数据。
- 首先会判断segment的名字看该消息在哪个segment里,通过文件名可以得到该offset数据的索引在00000000000000667788文件内;
- 通过二分查找法在.index内找到667790的索引数据在index=2这条纪录上。
- 根据.index文件中index=2的纪录得到第二列数据为指向.log文件的偏移量45;
- 通过得到的偏移量45到.log中定位到消息的起始位置即该消息的其他描述信息:消息体大小等等;
- 根据消息的起始位置及消息体大小,得到offset为667790的这条消息的消息体;
kafka高性能的秘密
- 分布式:kafka是分布式部署的,能通过横向扩展提升读写效率;
- 分区:通过分区的方式提升性能,分布分布在不同的Broker上提升读写效率,也是利用了分布式的特性;
- 日志编码:kafka的消息日志格式经过几个版本的迭代,将除了消息体KV之外的其他信息编码进行了优化,大大降低了消息的大小;
- 消息压缩:Kafka支持多种消息压缩方式(gzip、snappy、lz4、Zstandard),对消息进行压缩可以降低网络 I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对时延有一定的要求则不推荐对消息进行压缩。
- 批量处理:kafka的生产者发送多个消息到同一个分区的时候,为了减少网络带来的系能开销,kafka会对消息进行批量发送。该方式是通过在生产者配置文件中配置参数控制缓冲的数据大小batch.size(默认16k)以及提交间隔linger.ms(默认0ms)来控制。
- 顺序写:kafka的消息是顺序追加到.log文件内的,由于磁盘的特性,在磁盘中顺序写比随机写的性能高很多。
- 零拷贝:Kafka将消息先写入页缓存(page cache),消费者在读取消息时如果在页缓存中可以命中,那么可以直接从页缓存中读取,这就节省了从磁盘到页缓存的复制开销。
热门推荐
-
2、 优质文章
-
3、 gt
-
7、 openharmony
-
9、 golang
-
10、 Vue中input框自动聚焦